《表2 3种算法的分类结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
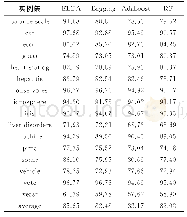
分别利用传统K-均值聚类[13]、传统熵加权聚类[14]和改进的熵加权聚类对图书馆数据集进行分类实验,并在F1-measure指标方面进行比较分析。为了合理有效性,在数据集上对每种算法重复运行10次取平均值。3种算法的分类结果对比如表2所示。可以看出,改进的熵加权算法在F1-measure指标的性能统计明显优于传统K-均值聚类和传统熵加权聚类,表现出更佳的准确度。同时迭代次数也有所降低,稳定性较好。
| 图表编号 | XD00125043000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.01 |
| 作者 | 李琳 |
| 绘制单位 | 郑州西亚斯学院 |
| 更多格式 | 高清、无水印(增值服务) |

![表2 6种分类算法用于强散射环境下目标分类结果对比[37]](http://bookimg.mtoou.info/tubiao/gif/GDJS202004002_03400.gif)


{kind=link}