《表4 识别准确率:藏文乌金印刷体文本图像自动分割技术研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
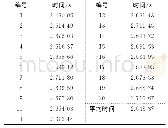
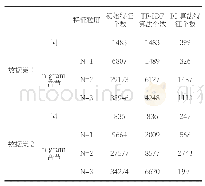
对不同扫描版喜马拉雅字体大小的藏文文本图像进行投影分割和连通域分割测试,发现文本字体越大,字丁之间的空隙就越大,这对分割越有利,相反,字体越小则分割越困难.投影分割法通过优化后主要分割错误的类型是字丁与音节分割符的黏连现象,例如:等,这种错误类型通过连通域分割有效解决.所以通过投影分割法和连通域分割法相结合的方式适合提取藏文音节字符,藏文音节提取错误的类型是藏文句子边界词末为的音节,由于藏文句子边界词与下一个句首音节之间无音节分割符或者楔形符,导致音节前后的字丁组合时发生错误.这类错误可以通过检测文本图像异常长度,这类组合错误的音节之间空隙很大,所以对这类黏连的音节进行适当膨胀,填充字符之间的空隙,即可分割.优化投影分割和连通域分割字丁的实验结果见表1和表2,提取藏文音节字符实验结果见表3.通过投影法和连通域相结合的分割方式构建了55488字丁数据集和470040音节数据集.在卷积神经网络模型模型上识别准确率分别达到了96.2%和98.9%,见表4.实验表明以藏文音节为识别单位优于字丁.藏文文本图像以藏文音节为分割单位的方式有利于藏文印刷体的识别.
| 图表编号 | XD00121913900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 多杰才让 |
| 绘制单位 | 青海师范大学、青海省藏文信息处理与机器翻译重点实验室、藏文信息处理教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}