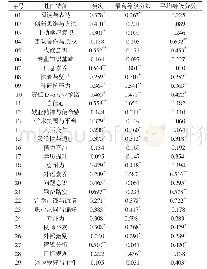
《表1 不同生成数量情况下最高分数与前10平均分数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
基于以上考虑,除对测试集整体进行美观度评判以外,还从中选择一批(实验设定为24)数量的文本输入数据,针对每一条文本数据生成不同数量的图片来观察其美学分数的分布。选择100、200、350、500、750、1 000共6种生成数量,针对选定的文本数据生成对应数量的图像,利用AADB模型计算生成结果的美学分数。图2展示了其中一条文本的结果。结果表明,美学分数在各个区间的分布状况是相近的,基本不受一次性生成数量的影响。6组结果都表现出生成图像的美学分数集中于5~7的区间内的分布状况,且随着生成数量的增加,高分图像的出现频率也越来越高。表1展示了6组分布结果中最高分数图像的分数与分数前10高图像的平均分数,表明了一次性生成数量越多,即使是处于高分分段的图像其整体的质量也会得到提高,也验证了本节第一段所述的情况。但面对最高分数的情况,因生成模型会以随机噪声作为输入来生成图像,这导致了其对生成结果的不可控性,所以生成结果会出现一定的扰动,使得最高分图像的分数与生成数量之间并不存在确定的正相关关联性。
| 图表编号 | XD00115221600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 徐天宇、王智 |
| 绘制单位 | 清华大学计算机科学与技术系、清华大学计算机科学与技术系 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}