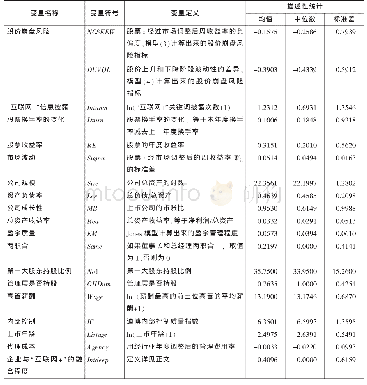
《表1 主要变量的描述性统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《回流对贫困地区农村儿童认知能力的影响——基于137所农村寄宿制小学的实证研究》
注:(1)本文初始调查样本数量为17924,删除了在性别、年龄、是否寄宿等控制变量中缺失或者回答选项相互矛盾的样本,同时学生问卷和班主任问卷匹配的过程中也损失了部分样本,最后得到12590个样本。我们比较了初始样本和最后用于分析的样本在因变量“阅读标准分”和核心自变量
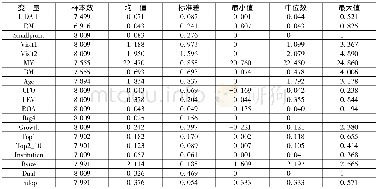
本研究利用倾向分数匹配方法,先对回流样本和非回流样本进行匹配,然后再对匹配后的样本进行各种估计。我们借鉴Imbens(2014)的方法,使用最邻近匹配,即在控制组中找到与处理组个体倾向得分值差异最小的个体,作为自己的比较对象。该匹配方法的一个优点是,按照处理个体找控制个体,所有接受处理的个体都会配对成功,处理组的信息得以充分利用。在匹配时,主要根据学生的个体特征(年龄、年级、性别、民族、是否寄宿、兄弟姐妹个数)、父母受教育程度和家庭经济状况(家庭资产指数)、班级规模和班主任受教育程度等来对每个样本计算倾向得分,去除回流儿童中倾向得分大于(小于)非回流儿童中倾向得分最大(最小)值的样本,最后得到匹配后的平衡样本。匹配后的结果见图1。从图1中可以看出,匹配后大多数观测值都在共同取值范围内,虽然利用倾向分数匹配方法会损失一些观测值,但统计分析发现匹配后的样本对初始样本仍有较好的代表性(1)。匹配后,控制组儿童和处理组儿童在个人特征、父母特征、家庭特征等方面基本一致,大多数变量的标准化偏差在匹配后都缩小了(2)。这说明匹配较好地平衡了回流和非回流样本。
| 图表编号 | XD00114395400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.30 |
| 作者 | 黎煦、朱志胜、陶政宇、左红 |
| 绘制单位 | 浙江大学经济学院 |
| 更多格式 | 高清、无水印(增值服务) |


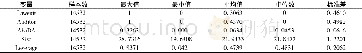

{kind=link}