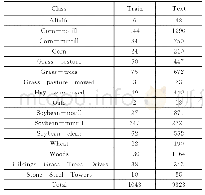
《表9 Indian Pines数据使用10%测试样本时的指标对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:加粗字体为OA、AA和κ最优值。
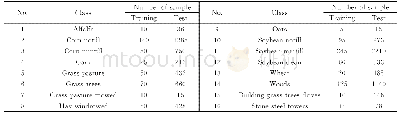
在大数据背景下,人们可以轻易地从互联网获取相当庞大的数据作为机器学习中的训练数据,但由于为这些数据进行标注往往要耗费大量的时间,因此人们获取的大量数据中只有很少一部分能够用于模型的训练,这对模型的训练是不利的,所以一个模型能否在小的训练样本下达到可以让人们满意的效果在实际应用中是相当重要的,该实验则是验证GCMC在小样本上的表现效果。本文训练样本的比例是10%,进行3组数据集的模拟实验,与对照算法的指标对比见表9—表11所示。从结果对比来看,当选取小样本模拟实验仍可达到较好的分类精度。
| 图表编号 | XD0011001100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.16 |
| 作者 | 邱云飞、王星苹、王春艳、孟令国 |
| 绘制单位 | 辽宁工程技术大学软件学院、辽宁工程技术大学软件学院、辽宁工程技术大学软件学院、辽宁工程技术大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}