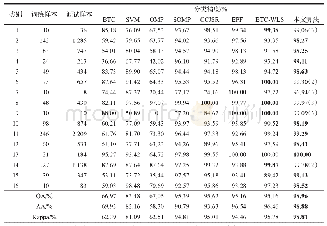
《表3 Indian Pines数据集在不同标记样本下的总体分类精度(分类精度±标准差)(%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
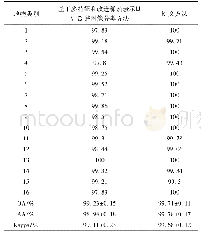
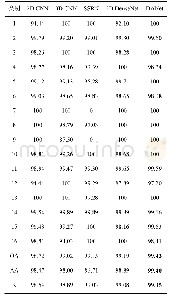
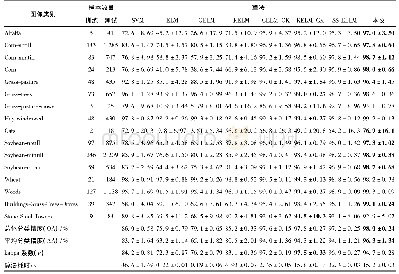
为了证明本文提出的算法的有效性,我们考虑最困难的情况,即每类地物仅只有5个有标记样本的情况。因为有标记样本点越少,分类就越难。从表4中可以看出,当每类只选取5个标记点时,本文算法SemiTCA总体分类精度OA相比SVM、Semi-HRS和ELP-RGF分别高24%、2%和2%。此外,Kappa系数也为最高,图4为该情况下各算法的全图分类效果图。红色圆圈内区域,可以看出本文算法的错分噪声点明显减少,在一定程度上体现了本文算法的优势。
| 图表编号 | XD00100249400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.25 |
| 作者 | 赵婵娟、周绍光、丁倩、刘丽丽 |
| 绘制单位 | 河海大学地球科学与工程学院、河海大学地球科学与工程学院、河海大学地球科学与工程学院、河海大学地球科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}