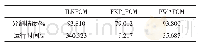
《表3 四种特征权重计算方案在Ucorp_A上的分类结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
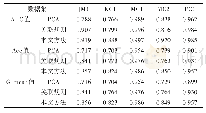
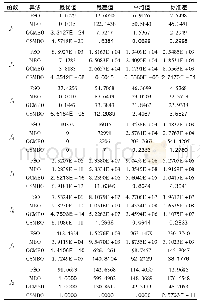
特征权重计算方法的好坏对文本分类效果影响很大,因此可以通过对文本分类效果的比较来评价特征权重计算方法的效果。本实验仍然使用维吾尔文文本数据集Ucorp_A。对数据集采用CDDTE[14]方法进行特征选择,用tf.idf方法来计算特征权重构造文本向量进行分类实验。当特征数为2 000的时候四个分类器的micro F1值都达到了各自的最高值。在本实验中,本文使用这2 000个单词作为文本特征,分别采用不同的三种特征权重计算方法tf.rf、tf.icf.te和tf.rf.icf.te来对每个特征进行加权,形成三种不同的特征空间。最后在不同的特征空间中对数据集的测试文本进行向量化,分别采用四种分类器NB、KNN、centroid和SVM对测试文本进行分类实验。表3给出了在Ucorp_A上的分类实验结果。
| 图表编号 | XD00107230900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 阿力木江·艾沙、殷晓雨、库尔班·吾布力、李喆 |
| 绘制单位 | 新疆大学网络与信息技术中心、新疆大学信息科学与工程学院、新疆大学信息科学与工程学院、新疆大学信息科学与工程学院、新疆大学网络与信息技术中心 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}