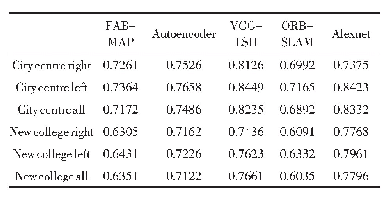
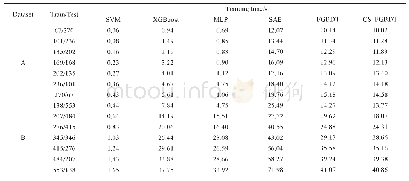
《表3 各算法在数据集A和B上的分类准确率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在分类准确率方面,如表3所示。MLP算法总体表现一般,尤其数据量较小时,其分类准确率明显较低,说明模型没有学到有效信息或者陷入局部最优。而SAE算法解决了神经网络的参数初始化问题,使模型加速收敛,且避开局部最优解,故其类性能优于MLP,同时表明特征分层表示有益于分类。XGBoost算法的准确率与SAE的相似,可知梯度提升树算法对NIR光谱数据有一定的分析能力,但性能劣于SVM。随着训练集增大,SVM的模型优势愈加明显,特别是在二分类实验下,其预测精度达到最高。相比其他模型,FGBDT结合特征分层表示和决策树集成思想,能有效学习数据特征,在各个规模数据下表现十分优越,尤其在小数据量上具有明显的分类优势。在此基础上,FGBDT结合代价敏感学习机制,以提升其分类性能,使得CS_FGBDT的预测精度更优。
| 图表编号 | XD00134717700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 杜师帅、邱天、李灵巧、胡锦泉、郑安兵、冯艳春、胡昌勤、杨辉华 |
| 绘制单位 | 北京邮电大学自动化学院、北京理工大学光电学院、桂林电子科技大学电子工程与自动化学院、北京邮电大学自动化学院、北京邮电大学自动化学院、中国食品药品检定研究院、中国食品药品检定研究院、北京邮电大学自动化学院、桂林电子科技大学电子工程与自动化学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}