《表1 法律条文预测结果:基于犯罪行为序列的法律条文预测方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
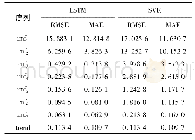
如表1所示,分别使用了BOW和Word2Vec作为词向量表示,相比于Word2Vec,BOW不论是在传统的随机森林、最大熵、支持向量机等模型,还是TextCNN、TextRNN等深度文本分类模型的表现上,都要弱于Word2Vec的词向量表示,因此本文最终选用Word2Vec作为模型的词向量表示方法。RF_fact_Word2Vec模型中分别使用案情描述作为输入的随机森林分类方法,MaxEntropy_fact_Word2Vec使用案情描述作为输入的最大熵分类方法,SVM_fact_Word2Vec使用案情描述作为输入的支持向量机分类方法,实验结果显示仅仅使用传统的文本分类方法和案情的事实描述作为数据输入,效果不佳。TextCNN_fact_Word2vec,使用TextCNN,在micro-F1值这一项的对比上,远胜于SVM_fact_Word2Vec,由此可见相比于传统文本分类方法SVM模型,TextCNN自动获取特征表达能力也显示出了其独特的优势。Text RNN_fact_Word2Vec弱于Text CNN_fact_Word2Vec,由此可见TextRNN在捕捉法律一类数据上并不是很占优势。TextRNN善于建模更长的序列信息,能够更好地表达上下文信息,从某种意义上来说,可以理解为对于链式结构的数据有着更好的处理效果。而犯罪行为序列这一类数据正好属于TextRNN模型善于处理的范畴。因此从这两方面出发,使用TextCNN_fact+TextRNN_criminalActSeq_Word2Vec,对案情描述这一文本信息使用TextCNN进行建模,对犯罪行为序列使用TextRNN进行建模,并将这两部分的模型进行融合,结果表明本文的模型性能相比不使用犯罪行为序列信息提升了约9%。这些实验结果表明,犯罪行为序列对于法律条文预测具有明显的提升作用。对于预测失败的样例,分析其对应的案情描述,可以发现其中一类是其包含的关于犯罪动作描述的信息较少,很难捕获到合适的犯罪行为序列;另外一类是文本长度较短,TextCNN无法捕获到充足的信息。
| 图表编号 | XD00107104500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.15 |
| 作者 | 陈文哲、秦永彬、黄瑞章、陈艳平 |
| 绘制单位 | 贵州大学计算机科学与技术学院、贵州大学贵州省公共大数据重点实验室、贵州大学计算机科学与技术学院、贵州大学贵州省公共大数据重点实验室、贵州大学计算机科学与技术学院、贵州大学贵州省公共大数据重点实验室、贵州大学计算机科学与技术学院、贵州大学贵州省公共大数据重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}