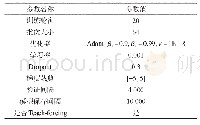
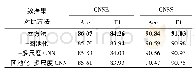
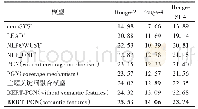
《表2 长文本摘要模型基本信息及评测结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:CNN/Daily Mail包含了来自美国有线电视新闻网和英国《每日邮报》的约30万篇新闻语料,每篇源文本包含平均766个词和29.74个句子,对应的标准摘要包含平均53个词和3.72个句子[17]。
表1以Rush等[9]的工作为基线整理了短文本摘要模型的基本信息和评测结果,表2以Nallapati等[17]的工作为基线整理了长文本摘要模型的基本信息和评测结果。从整体上看,在基于Seq2Seq模型的生成式摘要研究中,2015—2016年的工作主要集中于短文本摘要,2017—2018年逐渐转向长文本,大部分研究的评测结果相较于基线模型都有明显提升。结合第3节的梳理以及表中的数据可以进行以下主题的讨论。
| 图表编号 | XD00104780800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.24 |
| 作者 | 石磊、阮选敏、魏瑞斌、成颖 |
| 绘制单位 | 安徽财经大学管理科学与工程学院、南京大学信息管理学院、安徽财经大学管理科学与工程学院、南京大学信息管理学院、山东师范大学文学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}