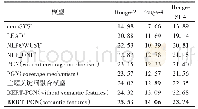
《表1 短文本摘要模型基本信息及评测结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:DUC2004是美国国家标准与技术研究院(NIST)文本摘要比赛用的小型数据集,包含500篇短文本,每篇文本包含4个由专家撰写的标准摘要,该数据集仅用于评测;英语Gigaword包含约950万篇新闻,取每篇新闻的首句作为源文本,新闻标题作为标准摘要[9],属于单句摘要数据集;LCSTS是大规模中
Rush等[9]在论文中提出了三种编码器方案:(1)词袋编码器,将输入序列中的词向量平均后作为语义向量,并不考虑词的顺序;(2)卷积编码器,使用时滞神经网络(time-delay neural network,TDNN)对词向量交替进行时间卷积(temporal convolution)和最大池化(max pooling)以计算出语义向量;(3)基于注意力机制的编码器,即ABS(attention-based summarization)模型。ABS模型基于词袋编码器,在计算语义向量时,不仅考虑输入序列中的词向量xi,还考虑解码器已输出的最近R个词的向量yRt-1,模型用yRt-1在输入序列和输出序列之间做对齐。ABS模型在DUC2004和英语Gigaword测试集上的表现并不理想(表1),生成的摘要存在着语法错误、事实歪曲等问题[9],但该工作作为一次有益的尝试,为后续研究带来了很多启发。编码器的工作相当于阅读一篇文本并理解其语义,这对机器来说无疑是相当具有挑战性的。人在阅读时,可能会采取选择性阅读、多遍阅读、分块阅读,还可能会借助外部资源理解文本,受此启发,学界提出多种编码器改进方案。由于注意力机制的设计和编码方式密切相关,本节在梳理编码方面的工作时将涵盖注意力相关内容。
| 图表编号 | XD00104780600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.24 |
| 作者 | 石磊、阮选敏、魏瑞斌、成颖 |
| 绘制单位 | 安徽财经大学管理科学与工程学院、南京大学信息管理学院、安徽财经大学管理科学与工程学院、南京大学信息管理学院、山东师范大学文学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}