《表1 数据集:基于改进Sequence-to-Sequence模型的文本摘要生成方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于改进Sequence-to-Sequence模型的文本摘要生成方法》
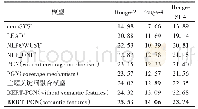
本实验数据源使用中文摘要数据集LCSTS(Large Scale Chinese Short Text Summarization Dataset)[14]。LCSTS数据集由哈尔滨工业大学(深圳)智能计算研究中心基于新浪微博收集整理而来,是一个大规模、高质量的中文短文本摘要数据集,在信息抽取方面应用较广。该数据集由成对的新闻短文和摘要组成,共约241万条数据,包括PART I、PART II和PART III三部分,其中PART II和PART III的数据用1~5之间的整数表示摘要的评分,5分最高,1分最低,如表1所示。
| 图表编号 | XD0035425400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 周健、田萱、崔晓晖 |
| 绘制单位 | 北京林业大学信息学院、北京林业大学信息学院、北京林业大学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}