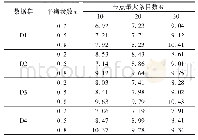
《表2 数据集:基于Biterm主题模型的新闻线索生成方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为测试本文方法的有效性及效率,以Pycharm作为开发工具,Python3.7作为编程语言,分别爬取人民网和新浪微博的真实新闻数据进行方法测试。以Python3的bs4和requests库函数为主,爬取人民网(1)2019年11月至2020年3月的新闻数据,包括新闻发布时间和新闻内容两个部分,共8 772条数据。使用Jieba分词对新闻内容进行分词,将分词结果以及新闻发布时间作为测试数据。另外,以Python3的lxml、requests和tqdm库函数为主,爬取新浪微博(2)央视新闻官方微博在2017年8月至2020年5月发布的新闻数据,主要包括新闻发布时间、新闻内容、新闻所属主题三个部分,共32 502条。同样使用Jieba分词对新闻内容进行分词,将分词结果以及新闻发布时间作为测试数据,新闻所属主题作为生成新闻线索准确率的评判标准。实验以人民网新闻作为长文本代表,微博新闻作为短文本的代表,数据集描述信息如表2所示。
| 图表编号 | XD00212869200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.25 |
| 作者 | 赵天资、段亮、岳昆、乔少杰、马子娟 |
| 绘制单位 | 云南大学信息学院、云南大学信息学院、云南大学信息学院、成都信息工程大学软件工程学院、成都信息工程大学软件自动生成与智能服务四川省重点实验室、云南大学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}