《表2 粗调最大准确率表:基于特征工程和KELM的化工过程故障检测与识别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
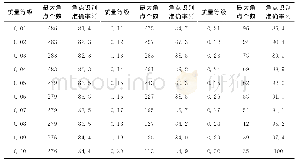
在对得到的ICA样本直接进行分类处理时,样本的测试精度最高为77.79%。此时正则化系数的最优值C=1,α=0.453。这是由于样本的变量顺序排布较乱且包含冗余,对神经网络的干扰性较大。采用互信息算法重新对变量进行选择后,再次进行分类。网络性能主要取决于正则化系数C与核参数α。C是用来权衡模型复杂度与模型正确率之间的参数,当C相对较大时,模型更为复杂,可以减少分类错误但容易产生过拟合。当C较小时,模型简单,训练效果容易变差。α则是衡量单个样本对分类准确度的影响,当其值较小时影响也较小。对不同的情况,网络结构参数是不一样的,对该仿真数据它们合适的取值在10-3~103。为了得到良好的训练精度,首先采用固定其中一个参数调整另一个的方式进行调整,以便大致确定最优区间。当最优区间确定后,采用遗传算法对区间进行优化得到最优参数。针对本文选取的样本,在适合的取值范围内进行调优。为了方便设置迭代步长,将调试区间划分成[10-3,1]、[1,100]和[100,103]3个层次。将每个区间均分成百份进行粗调。在此给出每一范围内最大准确率数据表,见表2。
| 图表编号 | XD00104568800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 任玉佳、王骥、田文德 |
| 绘制单位 | 青岛科技大学化工学院、青岛科技大学化工学院、青岛科技大学化工学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}