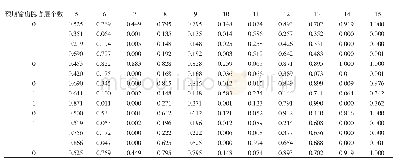
《表1 训练初期不同隐藏单元的训练误差》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
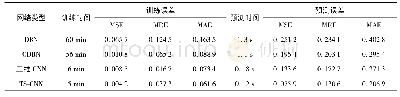
图4罗列了当单元数从2至15时的训练曲线,可见当训练到1 000步时,所有模型在训练集上的误差都可以下降到其误差平方和小于0.5。表1列出了不同网络结构在一定步数下误差的收敛情况。可以看出,当隐藏单元数小于5时,训练步数为149时,误差函数随隐藏层单元数的增加而减小,网络收敛更快。选择第149步的依据是,当步数过小时,4个模型均未收敛,当步数过大时,模型均已收敛从而无法对收敛快慢做出比较。当隐藏单元数大于5时,选择第199步训练情况进行比较,这是因为网络中随机化的初始参数过多,训练还未达到稳定状态,从而使得预测结果有很大的随机性。此时,误差函数反而随隐藏层单元数的增加而增大,网络的表现并没有得到明显的提高。可以看出,过多的隐藏单元数不仅造成了训练成本的增加,并且容易造成数据过拟合的情况出现。因此,在这个案例中,设定最好的隐藏单元数为5。
| 图表编号 | XD00104564100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 华丰、田亮、邱彤 |
| 绘制单位 | 清华大学化学工程系、工业大数据系统与应用北京市重点实验室、中国石油兰州化工研究中心、清华大学化学工程系、工业大数据系统与应用北京市重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}