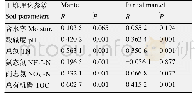
《表1 样本相似距离统计结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
现有的度量学习算法通过建立距离度量函数的优化模型,约束正样本对相对于负样本对的距离学习一个投影度量空间或马氏距离,从而获取具有强分辨能力的度量模型。基于度量学习的样本距离(相似性)函数构造方法的假设前提是训练数据和测试数据的分布与总体分布相同。然而由于行人再识别样本特征变化的复杂性,包含有所有行人外观变化的样本总体分布是一个体量庞大的集合。已有的公开数据集仅仅是样本总体中很小的一部分。这导致了行人再识别任务中的小样本问题,现有的行人再识别度量模型通常在训练样本上过拟合。对此,本文中基于VIPeR和iLIDS数据集进行了分析。首先,通过3.1节中的度量学习算法,在VIPeR数据集上训练得到度量模型;其次,基于训练得到的度量模型对VIPeR和iLIDS数据集中样本分别进行相似性度量,统计两个数据集的正负样本在度量空间中的距离分布的均值,结果如表1所示。表1中给出了两个数据集中正负样本总体在度量空间中的相似距离的均值。由统计结果可以看出,基于现有的度量学习模型,目标域和源域数据在投影空间中的分布存在着巨大的差异。导致差异的原因是由于行人图像跨越场景时外观特征变化剧烈,现有模型训练数据过少,训练数据与测试数据存在较大差异。
| 图表编号 | XD00102819000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.15 |
| 作者 | 宋丽丽 |
| 绘制单位 | 成都理工大学工程技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}