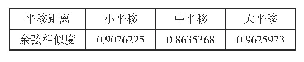
《表1 样本实验结果及余弦相似度比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文选取NLPIR微博语料库[14],先抽取大约20万条数据进行训练与实验,同时抽取大约100万条数据进行横向对比实验。对两组实验原始语料数据作相同预处理。首先去掉正文插入时间,正文发布时间,转发、来源、评论数目等对实验无影响的因素,同时去掉无用的符号和停用词;然后对过滤后的数据进行分词;再把数据作为输入代入word2vec模型中进行训练,得到每个词的向量表示并输出文件“vector.bin”,计算两个词向量之间的余弦值得出词向量之间的余弦相似度。以输入数据样本作为样例测试词向量训练结果,选取余弦相似度值最靠前的2个作为样本示例,实验结果及余弦相似度比较见表1所列。
| 图表编号 | XD0077834700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.20 |
| 作者 | 蔺伟斌、杨世瀚 |
| 绘制单位 | 广西民族大学软件与信息安全学院、昆明理工大学管理与经济学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}