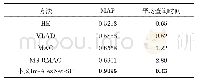
《表2 平均时间代价:基于LSH的时间序列DTW相似性查询》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
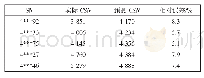
我们的实验分别在4种不同的数据集上进行测试,表2描述了在进行范围查询时不同方法的运行速度,图4和图5分别展示了在阈值不变的情况下,不同方法在不同数据集上的召回率和准确率.通过分析可以得出LB_DTW虽然查全率和准确率都较高,但是在查询速度较DTW并没有明显的改善,因此可以判断对于某些数据集,下界的紧致性并不是很好,没有起到很好的剪枝作用,甚至执行时间有时会超过暴力算法.而基于集合的算法即STS3虽然在很短的时间内就可以完成相似性序列的查询,但是通过实验结果得出,STS3的查全率和查准率没有达到理想的指标,在某些情况下,不能够近似于DTW度量完成相似性序列的查询.而我们的方法虽然召回率略低于Lb_DTW算法,但是查询速度明显快于Lb_DTW,证明TQLD算法的过滤能力要优于Lb_DTW.因此我们的算法在保持较好的召回率的情况下,较现有算法有效地提高了DTW相似性查询速度.
| 图表编号 | XD0096864600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 李敏、于长永、张峰、马海涛、赵宇海 |
| 绘制单位 | 东北大学计算机科学与工程学院、东北大学计算机科学与工程学院、东北大学计算机科学与工程学院、东北大学计算机科学与工程学院、东北大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}