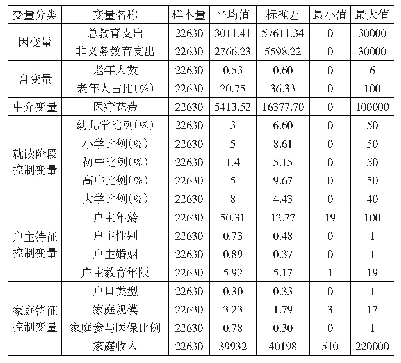
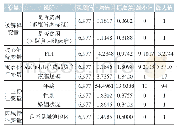
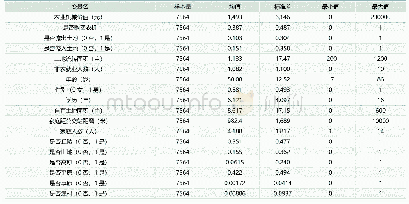
《表2 主要微观变量的描述性统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《中国居民消费内需不足的经济解释:基于性别比失衡视角》
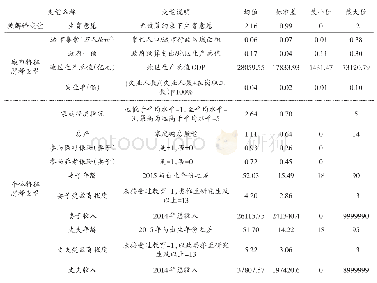
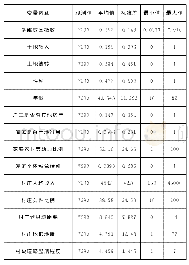
在我国统一实行的计划生育政策下,性别比失衡问题具有典型的区域特征,因此本文尝试选择合适的区域工具变量。Eberstein(2011)曾提出,可以采用我国各省(区、市)的超生行为罚款金额作为该地区人口性别比的工具变量。然而,在实际应用时,我们发现它与当地居民收入状况存在较高相关性,即收入与消费水平较高的地区(如上海市等),其罚金数额也较大。我们知道,人口性别结构与婚姻市场具有密切关系,随着该地区人口性别比上升:一方面会导致当地“光棍”增多,即适龄男性的未结婚人数增多,男性群体的婚姻匹配压力增大;另一方面,为防止男性落入“光棍”大军,家长也会增加对提升其“议价能力”有利的投资,比如汽车与房子等高档品的购买,以及早期教育投资的增加。由此分析,本文决定选用所在地区的男性平均受教育程度(averagedu)与适龄男性未婚率(unmarry)作为工具变量。同时,虽然消费与储蓄水平会在一定程度上影响个体能否找到配偶的概率,但地区的“适龄男性未婚率”作为一个宏观层面的变量,性别比的失衡会直接影响到“适龄男性未婚率”。而消费水平与之并无直接的关系。同时,根据之前人力资本的相关理论,性别比失衡会增加家庭对于男性的人力资本投资,因而提高区域性宏观变量“男性平均受教育程度”,同时男性的平均受教育程度与消费并无直接关系。因此,这两种工具变量与个体或家庭的消费并无较大关联,而已有研究文献也证实,它们是较为有效的工具变量(栗志强,2013)。鉴于微观数据库的局限性,本文借助2011年“中国综合社会调查”(Chinese General Social Survey,CGSS)的分省(区、市)抽样微观数据库,按照分省(区、市)、分城乡的方式与CHNS进行匹配,从而获取两个工具变量的样本数据。因此,模型(2)采用两阶段最小二乘法(two-stage least squares,2SLS)进行估计,并对工具变量的有效性和过度识别等问题进行检验。主要变量的描述性统计见表2。
| 图表编号 | XD0093290900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.15 |
| 作者 | 戴圣涛、卜京 |
| 绘制单位 | 北京大学国家发展研究院、南京大学经济学院 |
| 更多格式 | 高清、无水印(增值服务) |
{kind=link}