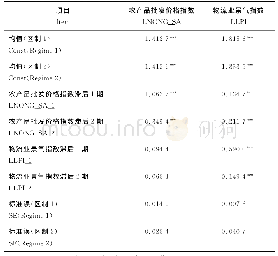
《表5 MSWE@CFM_sam_SFM的λ与影响分》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
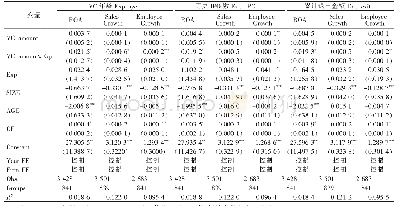
在基于神经网络的词表示学习中,如果词向量的维数设置过大,会导致模型训练时间较长,但是向量中包含的特征信息较多。如果词向量的维数设置过小,虽然模型训练时间较短,但是词向量中包含的特征信息就较少。只有取得合适的词向量维度值,才能在词相似度和文本分类等评测任务中发挥出更好的性能。而在表4、表5和表6中,词向量的维度设置得越小,则在词相似度评测任务中表现出的性能越好。该结论和基于神经网络的词表示学习中关于维度的认识较为不同。在基于神经网络的词表示学习中,把当前词语与其上下文词语的结构关系嵌入到固定长度的向量空间时,过大或过小的向量维度会引起特征的冗余或丢失。此外,在不同的语料上,相同的算法可能取得的最佳维度也不相同。本文算法的实质是矩阵的联合分解,以当前词语与上下文词语构成的CFM特征矩阵为待分解目标矩阵,以同义词与反义词特征矩阵SAM和属性语义特征SFM作为辅助分解矩阵。在分解算法中,当较小的维度被选择时,分解算法往往会保留关键特征,同时删除冗余特征,此外,扩大了不同特征之间的差异性,以便于更好地为后续的应用服务。当然,过小的维度也同样会导致特征的严重丢失,导致在词相似度评测中表现出较差的性能。对于分解算法的维度,主要依赖于数据之间的相关性,即数据之间的关联性越强,则适合降维到更小的维度,如果数据之间的关联性较弱,则适合降维到更大的维度。本文主要是研究如何分解CFM特征矩阵,而该矩阵中的每个值均是词语之间的上下文关系。因此,降维的维度数越少,其词表示学习性能越好。
| 图表编号 | XD0091822900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 冶忠林、赵海兴、张科、朱宇 |
| 绘制单位 | 青海师范大学计算机学院、陕西师范大学计算机科学学院、青海省藏文信息处理与机器翻译重点实验室、藏文信息处理教育部重点实验室、青海师范大学计算机学院、陕西师范大学计算机科学学院、青海省藏文信息处理与机器翻译重点实验室、藏文信息处理教育部重点实验室、青海师范大学计算机学院、青海省藏文信息处理与机器翻译重点实验室、藏文信息处理教育部重点实验室、青海师范大学计算机学院、青海省藏文信息处理与机器翻译重点实验室、藏文信息处理教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
![表2 实施前、后护理质量与病区管理质量评分对比_[(x±s)分]](http://bookimg.mtoou.info/tubiao/gif/YXSL202008095_01500.gif)



{kind=link}