《表7 MSWE@CFM_SAM+CFM_SFM的λ与影响分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
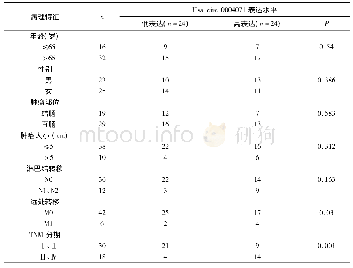
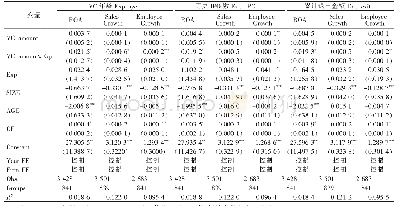
从表2中可以发现,MSWE@CFM_SFM、MSWE@CFM_sam_SFM、MSWE@CFM_SAM和MSWE@CFM_SAM+CFM_SFM等的多源信息融合方式是行之有效的,且其性能在词语表示学习的相似度评测任务中均优于单一的结构特征模型,例如,SGNS、CBOW、Huang、Glove和DEPS等模型。但是上述实验是在词表示向量长度为100,且IMC算法中λ为0.1的设置下所得到的数据结果。因此,表4~表7中详细分析了词表示向量长度和式(13)中的λ在Rare Words评测集上对词表示性能的影响。的取值为30、50、100、150和200,λ的取值为10-1、10-2、10-3、10-4和10-5。
| 图表编号 | XD0091823000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 冶忠林、赵海兴、张科、朱宇 |
| 绘制单位 | 青海师范大学计算机学院、陕西师范大学计算机科学学院、青海省藏文信息处理与机器翻译重点实验室、藏文信息处理教育部重点实验室、青海师范大学计算机学院、陕西师范大学计算机科学学院、青海省藏文信息处理与机器翻译重点实验室、藏文信息处理教育部重点实验室、青海师范大学计算机学院、青海省藏文信息处理与机器翻译重点实验室、藏文信息处理教育部重点实验室、青海师范大学计算机学院、青海省藏文信息处理与机器翻译重点实验室、藏文信息处理教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}