《表1 0 HCR数据集上的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
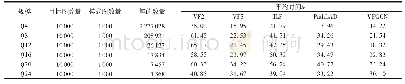
在同一数据集下,使用不同的特征表示形式对短文本构建不同的特征矩阵,对比使用和不使用SMOTE处理训练集,实验结果如表10所示,其中,“Pres”代表特征词汇存在,“Freq”代表特征词汇出现的次数,参数α设置为2。另外选取2种经典的分类方法和SANT模型作为基准算法,LR为逻辑回归(Logistic Regression),是一种广泛使用的分类器[24],LASSO是一种具有代表性的稀疏学习方法[24]。
| 图表编号 | XD00156653000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.15 |
| 作者 | 刘树栋、王磊、武璟珑、徐亮 |
| 绘制单位 | 中南财经政法大学人工智能法商应用研究中心、中南财经政法大学信息与安全工程学院、中南财经政法大学人工智能法商应用研究中心、中南财经政法大学信息与安全工程学院、中国电子信息产业集团有限公司信息中心、京东商业提升事业部 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}