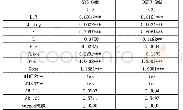
《表1 模型1-2对纵向一体化指数YTH估计结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
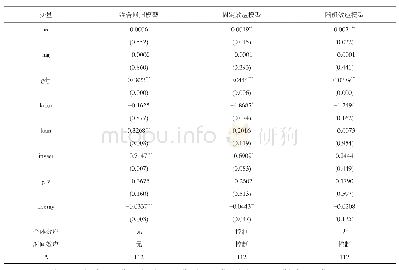
注:1、括号内数字为t检验值,**、***分别代表P值在5%和1%水平显著。
本文以中国大陆地区31个省、市、自治区为研究对象,工业统计年鉴有增加值数据的年代2003—2007年5个时期,剔除西藏地区,面板数据由150组观测值组成。采用面板数据是因为:面板数据通常含有很多数据点,因此会带来更多信息、更多自由度和更多变化性,而且可以减少多重共线性问题;其次,面板数据可以更好地控制个体差异,识别和度量纯时间序列和纯横截面数据所不能发现的影响因素。原始数据来自中宏产业集群数据库,以及历年《中国工业经济统计年鉴》和《中国统计年鉴》。使用EVIEWS7.2软件对上述计量模型进行估计。一方面根据豪斯曼检验确定随机效应模型是否优于固定效应模型,另一方面根据伍德里奇的建议,对于使用地域面积比较大的行政省份作为样本,固定效应估计比随机效应更加可信[11],因此使用固定效应模型。由于横截面远远大于时间序列,采用横截面时间序列可行广义最小二乘法FGLS,在面板数据存在异方差和时间序列相关性时,可以提供可靠的估计。
| 图表编号 | XD0060925000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.10 |
| 作者 | 张贞、陈益民 |
| 绘制单位 | 南京林业大学经济管理学院、南京林业大学经济管理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}