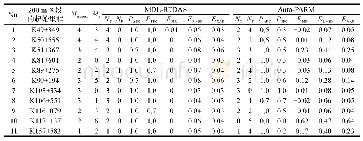
《表1 现有语步识别研究的模型及效果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
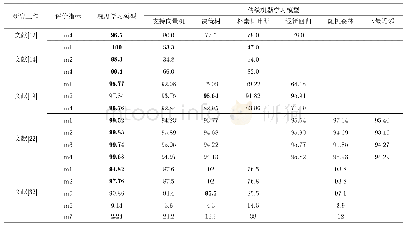
如何通过自动化的技术手段,从非结构化的科技论文摘要中,自动识别出相关的语步内容(如自动识别摘要中的表达论文“研究目的”的句子)得到了很多科研人员的关注。这些科研人员采用朴素贝叶斯模型(Naive Bayesian Model,NBM)[7-8]、隐马尔可夫模型(Hidden Markov Model,HMM)[9-10]、支持向量机模型(Support Vector Machine,SVM)[11-14]和条件随机场模型(Conditional Random Field,CRF)[2]等方法实现了科技论文摘要中的自动语步识别。目前语步识别研究中所采用的自动识别模型、能够识别的语步类型以及识别的效果如表1所示。除Teufel等的论文语步研究对象为全文外[7],其余的研究对象为论文摘要。
| 图表编号 | XD009133100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.25 |
| 作者 | 丁良萍、张智雄、刘欢 |
| 绘制单位 | 中国科学院文献情报中心、中国科学院大学图书情报与档案管理系、中国科学院文献情报中心、中国科学院大学图书情报与档案管理系、中国科学院武汉文献情报中心、中国科学院文献情报中心、中国科学院大学图书情报与档案管理系 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}