《表1 4 僵尸企业预测结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
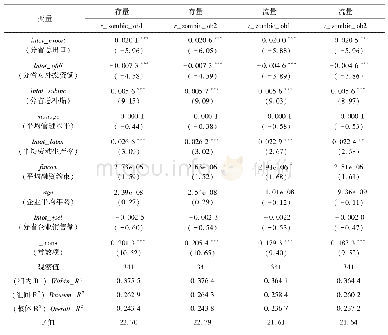
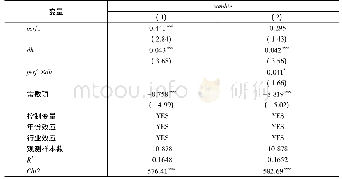
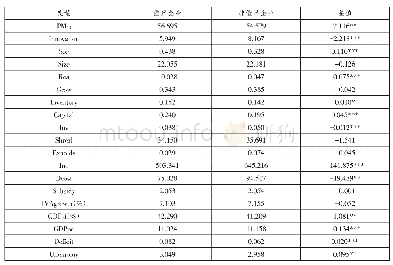
本文利用表13中的回归结果,对数据进行了样本内和样本外预测。预测的关键在于选择合适的临界值:若临界值较低,则犯“第二类错误”的概率较高,反之则容易犯“第一类错误”。本文使用的是非配对数据,因而采用样本内僵尸企业的比例0.0503(=僵尸企业数386家/企业总数7 675家)作为临界值,使得两类错误发生的概率相当。本文中随机效应模型和混合模型的预测结果非常接近,受篇幅限制,仅报告了随机效应模型预测结果。从表14中可以看出,样本内和样本外识别准确率分别高达88.57%和96.58%。
| 图表编号 | XD009126600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.04.03 |
| 作者 | 周琎、冼国明、明秀南 |
| 绘制单位 | 南开大学经济学院、南开大学经济学院、南开大学经济学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}