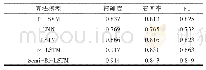
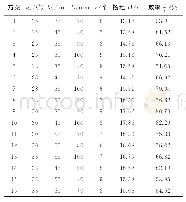
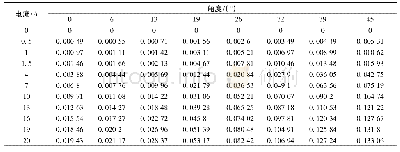
《表2 现有研究所采用的训练样本量、N-gram取值、是否去停用词、词频加权方式对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对前人工作进行分析时,笔者发现在语步自动识别的研究中,训练样本规模以及一些精细的特征(如N-gram的N取值、是否去除停用词、词频加权方式)对模型识别效果的影响尚未形成统一认识。各研究者在训练样本规模选择、N-gram的N取值、是否保留停用词以及词频的加权方式上,各自有其观点和估法,尚无一致性的结论。已有研究所采用的训练样本量、N-gram取值、是否去除停用词、词频加权方式如表2所示,其中训练样本量统计的是摘要数量。
| 图表编号 | XD009072000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.25 |
| 作者 | 丁良萍、张智雄、刘欢 |
| 绘制单位 | 中国科学院文献情报中心、中国科学院大学图书情报与档案管理系、中国科学院文献情报中心、中国科学院大学图书情报与档案管理系、中国科学院武汉文献情报中心、中国科学院文献情报中心、中国科学院大学图书情报与档案管理系 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}