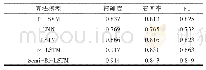
《表1 模型对比结果:基于半监督与词向量加权的文本分类研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文实验数据采用清华大学实验室整理的中文新闻分类数据集,包含大约30 000个样本,分为10个类别。按有监督部分使用训练集和测试集6:4的比例进行训练。基于半监督方式模型进行训练时,主动学习部分拿出有标注数据集样本200个训练初始分类器,每次迭代从预测结果相同的样本集中取出置信度较高的20个样本,分别加入一些不同分类特征词作为噪声重新输入回分类器进行训练。本实验对分类结果的评价指标依旧沿用传统评价方式,采用准确率和召回率评价模型性能优劣与泛化能力高低,采用F1Score评价模型预测能力的稳定性,同时将传统的有监督模型作为对比试验,采用半监督和不采用半监督的训练方式进行对比。所有算法模型训练结果如表1所示。
| 图表编号 | XD00224776800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.15 |
| 作者 | 宋建国 |
| 绘制单位 | 山东科技大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}