《表1 部分停用词:基于词典的文本极性计算及分类研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
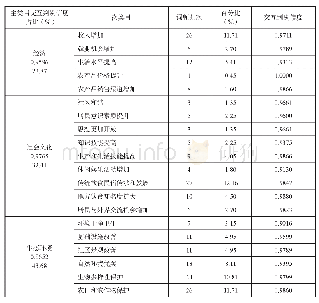
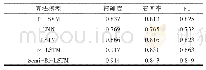
首先对数据进行清洗,主要是删除没有意义的数据以及一些重复数据。删除这类数据可以使用Excel中的函数或者使用正则表达式完成。接下来对文本进行切分、分词和去停用词等操作。由于评论文本内容通常比较简短,故只进行分词和去停用词即可,分词就是把句子切分为一个个单独的词语,它是进行文本分类的基础。分词完成之后还需进行名词、形容词、副词等词性标注。在分词时需要加载用户词典,用户词典由未登录词、候选情感词以及用户自己构建的词典组成。在中文中,一篇文本的内容是通过名词、动词、形容词、代词、介词和连词等词汇构成,其中,名词等实词对文本情感极性计算有极大的帮助作用;而介词、连词、冠词等虚词以及一些常用词汇则不能提供太多的帮助,将这些对文本情感极性计算帮助不大的词称作停用词。在进行文本处理时往往都需要去停用词,比如英文中的“the、of、and、to、for”等,汉语中如“的,地,这个,那个”等助词。在本文中针对研究内容共收集停用词1208个,部分如表1所示。分词和去停用词可以使用jieba完成。至此,实现文本的预处理操作,粗略筛选出有用词条。
| 图表编号 | XD00139081100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 薛兴荣、靳其兵 |
| 绘制单位 | 北京化工大学信息科学与技术学院、北京化工大学信息科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}