《表1 部分共现词组:基于词共现的文本分类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
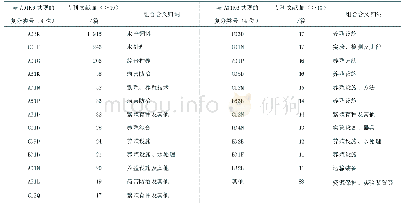
首先,对采集到的web政策文本进行预处理,包括数据清洗、分词、去停用词等操作;其次统计词频完成去除低频词,计算关键词TF-IDF权值;再进行分类对比实验,第一次实验利用TF-IDF算法提取关键词,得到关键词1492个;第二次实验利用词共现算法从每类文档中提取共现率为前30的关键词组,共300个关键词,远少于前者提取的关键词数量,有效降低了空间维度,每类文档提取的部分共现词组如表1所示。之后将文档数据按7:3的比例分为训练集和测试集两部分,其中训练集1305篇,测试集444篇。最后利用SVM算法分别完成文本分类。实验中涉及到的算法均由python语言实现,分词工具选用结巴分词模块,中间分词、提取关键词等保存为TXT及CSV格式文件。
| 图表编号 | XD0024176500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.09.01 |
| 作者 | 和志强、杨建、王丽鹏 |
| 绘制单位 | 河北经贸大学信息技术学院、河北经贸大学信息技术学院、河北经贸大学信息技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}