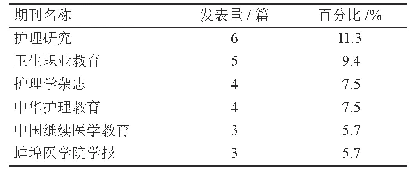
《表3 Yamamoto等实验得到的各语步排名前6位的重要词项》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
通过总结已有研究发现,绝大部分研究采用的训练样本数量较少,从数千条到数万条不等,同时相关研究都没有明确提及在训练样本数量从少到多的过程中,识别效果的变化情况如何。在N-gram取值方面,Mc Knight等[12]、Ito等[14]、Yamamoto等[13]仅选取一元词作为特征,而Shimbo等[11]、Hirohata等[2]、Kim等[15]选取一元词和二元词为特征。在是否去除停用词方面,许多研究并未提及是否在文本预处理中进行了去除停用词的操作,而Yamamoto等[13]、Hirohata等[2]、Ruch等[8]研究发现停用词在语步自动识别中发挥了较大作用,Yamamoto等[13]通过卡方检验的方式,得到各语步最重要的前6个词项,如表3所示,其中很多语步中的词项是停用词(如Purpose语步中的to,Method语步中的in和by等)。在词项加权方式上,Ruch等[8]采用三种词频加权方式——TF-IDF、卡方值计算和DF-Thresholding进行实验,发现TF-IDF算法的语步识别效果较差,原因在于TF-IDF算法适用于对意义词(Content Word)进行加权,而语步中包含大量功能词(Function Word)。这些词虽然没有完整词汇意义,但是有语法意义或语法功能,若采用TF-IDF方式,将削弱这些词的重要性。而Mc Knight等[12]、Shimbo等[11]、Ito等[14]、Kim等[15]直接统计语步中单词的词项频率作为特征。
| 图表编号 | XD009070600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.25 |
| 作者 | 丁良萍、张智雄、刘欢 |
| 绘制单位 | 中国科学院文献情报中心、中国科学院大学图书情报与档案管理系、中国科学院文献情报中心、中国科学院大学图书情报与档案管理系、中国科学院武汉文献情报中心、中国科学院文献情报中心、中国科学院大学图书情报与档案管理系 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}