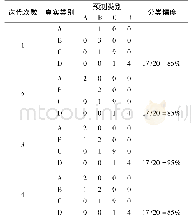
《表2 模型的混淆矩阵:随机森林与GIS的泥石流易发性及可靠性》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
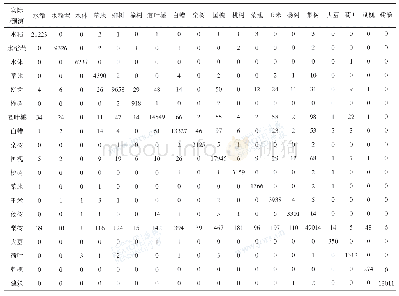
模型预测结果可分为分类型(0和1)和概率型结果(0~1).考虑到各模型的实现原理的侧重不同,进行两种类型(分类和概率)结果的对比能更客观全面地比较各模型预测效果,同时也为今后的不同结果应用提供基础,如分类型结果可直接用于评估今后建设规划中两类错误的可能代价,概率型结果适合于进一步的泥石流危险性和风险性评价.评价方式是将总样本实际值与模型给出的预测值进行对比.本节先讨论模型决策函数给出的二分类型预测结果,其分别代表灾害的不发育(0)或发育(1),将它们与实际值比较,可得混淆矩阵(表2),其中行代表实际的分类,列代表模型预测的分类.根据表2下方公式计算得到各种模型分类预测能力评价指标.表2中4种模型各指标明显高于完全随机结果,除了RBF-SVM泥石流查全率低于50%.模型整体分类预测能力首先依据ROC曲线下面积AUC,如2.7节所述其能考虑各个分类阈值下的情况,因此更全面;其次考虑全局预测精度.依此标准预测能力排序依次是RF、RBF-SVM、QDA、LSVM.由此可见,在本文考虑的泥石流影响因子较多时,线性模型的易发性预测能力相对较差.
| 图表编号 | XD0086026700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.01 |
| 作者 | 张书豪、吴光 |
| 绘制单位 | 西南交通大学地球科学与环境工程学院、西南交通大学地球科学与环境工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}