《表3 脉冲神经拟态芯片国内外研究现状》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
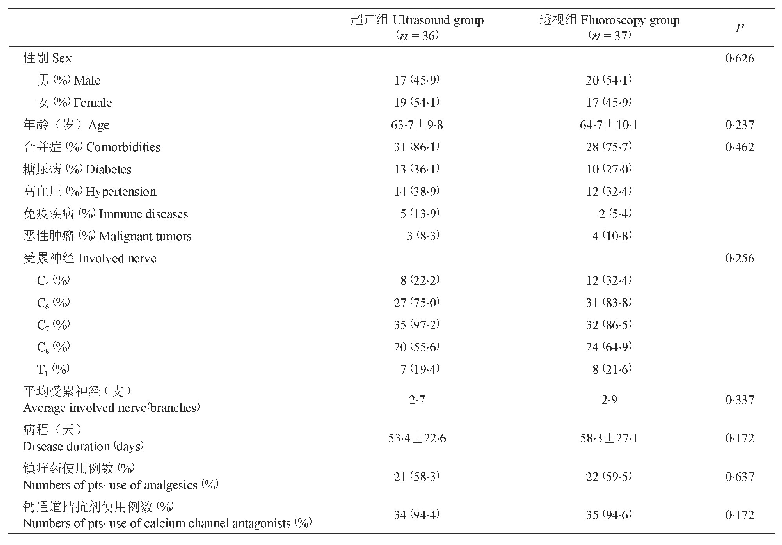
近年来,世界上著名的学术研究机构和国际半导体公司都在积极研究和开发基于脉冲的神经拟态电路[38-45]。如表3所示,基于SNN的神经拟态计算硬件比基于传统DNN的硬件加速器具有更高的能量效率。大多数最先进的神经拟态计算芯片[39-41,44]都是基于成熟的CMOS硅技术对SNN进行ASIC设计,通过SRAM等存储器模拟实现人工突触,并利用关键的数字或模拟电路仿生实现人工神经元。其中最具有代表性的是IBM公司研发的基于CMOS多核架构TrueNorth芯片[40],当模拟100万个神经元和2亿5 000万个突触时,该芯片仅消耗70 mW的功耗,每个突触事件仅消耗26 pJ的极高能量效率。然而,为了模仿生物突触和神经元的类脑特性,电子突触和神经元需要高度复杂的CMOS电路来实现所需的人工突触和神经元的功能,如图2所示。以IBM的TrueNorth芯片为例,它包含54亿个晶体管,在28nm工艺下占据4.3 cm2的面积。因此,这一类基于脉冲的神经拟态CMOS硬件电路使用大量的晶体管,并导致耗费非常大的芯片面积。加之,现有的大多数神经拟态芯片[39-41,44]由于其计算单元与存储单元在局部依然是分离的,这在用于神经元的CMOS逻辑电路和用于突触的SRAM电路之间依然存在局部的存储壁垒问题和能量效率问题,所以实际上还不是真正意义上的非冯·诺依曼体系结构。不过最新的具有三维堆叠能力的非易失性存储器(NVM)技术或存内计算技术(in-memory computing)有望解决这一问题。
| 图表编号 | XD008595500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 任源、潘俊、刘京京、何燕冬、何进 |
| 绘制单位 | 北京大学深圳研究院系统芯片设计重点实验室、北京大学深圳研究院系统芯片设计重点实验室、北京大学深圳研究院系统芯片设计重点实验室、北京大学深圳研究院系统芯片设计重点实验室、北京大学深圳研究院系统芯片设计重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}