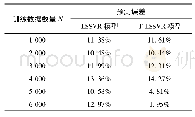
《表1 不同行为下姿态估计测试误差对比Tab.1 Comparison of test errors of human pose estimation in different behavior vi
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
mm
基于概率主成分分析(probabilistic principal component analysis,PPCA)方法[16],对该三维人体姿态估计模型做出了在Human3.6M数据集上部分人体动作行为的姿态估计测试,跟传统的方法估计的误差对比结果如表1所示。Ionescu等[15]提出Human3.6数据集,并对该数据集进行了傅里叶核近似测试。Zhou等[12]用二维姿势标注来训练CNN联合回归量和单独的3D mocap数据集,从而学习三维稀疏基础来建立三维估计模型。本文模型的姿态估计测试在各个人体动作行为上的误差均为最低值,在吃东西行为上误差为79.12 mm,在坐行为上误差为118.96 mm,在走路行为上误差为78.28 mm,在打招呼行为上为95.17 mm,性能相比前两种方法均有不同程度的提升,平均误差达到92.88 mm,相比Ionescu等[15]的傅里叶核近似法提高了31.8%,相比Zhou等[12]的三维稀疏回归法提高了5.7%,估计效果明显更加优越。3种方法平均误差对比如表1所示。
| 图表编号 | XD0077705000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.01 |
| 作者 | 肖澳文、刘军、张苏沛、杜壮、孙思琪 |
| 绘制单位 | 智能机器人湖北省重点实验室(武汉工程大学)、武汉工程大学计算机科学与工程学院、智能机器人湖北省重点实验室(武汉工程大学)、武汉工程大学计算机科学与工程学院、智能机器人湖北省重点实验室(武汉工程大学)、武汉工程大学计算机科学与工程学院、智能机器人湖北省重点实验室(武汉工程大学)、武汉工程大学计算机科学与工程学院、智能机器人湖北省重点实验室(武汉工程大学)、武汉工程大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}