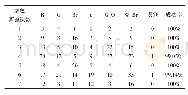
《表2 PNN分类识别结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于气体传感器阵列和非线性信号分析技术的龙井茶品质检测方法研究》
在PNN分类识别龙井茶样品品质实验过程中,总共有6个储存时间节点过程,每个节点过程采样16个样本,从其中随机选择10个样品检测信息作为训练集,其余6个样品信息作为测试集。得到训练集样品数量为60个,测试集样品数量为36个。在PNN模型建立过程中,Spread代表PNN的扩散速度,如果其值趋近于0,则网络相当一种最邻分类器,其默认取值是0.1,Spread的取值对模型的判别结果有决定性影响,取值越大就越接近线性函数。为了对PNN模型进行优化,Spread的优化区间取值是[1×10-2、2×10-2、3×10-2、4×10-2、5×10-2、6×10-2、7×10-2、8×10-2、9×10-2、1×10-2]。我们选择训练集识别率和测试集识别率一并为最高时的PNN参数作为最优模型。经过训练测试实验,结果表明Spread=1×10-2时PNN模型为最优配置。在最优模型中,训练集样本分类识别正确率为100%,测试集分类识别正确率为93.3%,具有较好的分类识别效果。
| 图表编号 | XD007553400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.09.01 |
| 作者 | 汤旭翔、余智 |
| 绘制单位 | 浙江工商大学实验室与设备管理处、浙江工商大学网络信息中心 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}