《表2 不同算法最优参数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
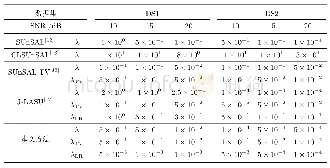
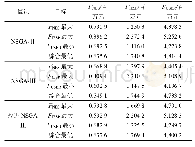
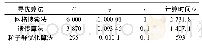
依据所设置的限定误差,利用三个数据集的训练样本分别对三种算法进行训练,结果如图4至图6以及表2所示。对于glass数据集与wine数据集,各算法的预训练学习速率最优值αopt=0.65,对于seeds数据集αopt=0.60;三种算法中只有WMA具有动量参数,其最优值在三个数据集中均为μopt=0.5。在对三个数据集训练的过程中,对于DAE-ESA的反向调优学习速率最优值βopt为0.80与0.75,DAE-CSA的βopt为0.65与0.60,DAE-WMA的βopt为0.70与0.65。在收敛速度方面,相对于glass、seeds与wine三个数据集,DAE-WMA的网络训练最小迭代次数分别为35、32、34,整体优于DAE-ESA的49、43、46与DAE-CSA的47、43、42。
| 图表编号 | XD0067451200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.15 |
| 作者 | 李楠、侯旋 |
| 绘制单位 | 中国(西安)丝绸之路研究院、西安财经学院管理学院、空军工程大学航空工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}