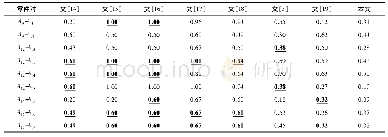
《表1 常用相似度计算方法Tab.1 Similarity measures used frequently》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Bhattacharyya系数的改进相似度度量方法》
随着“信息过载”问题的日益突出,个性化推荐服务研究备受青睐。其中,协同过滤技术得到了广泛的研究和应用,在基于近邻的协同过滤推荐算法中,相似度的计算至关重要[1-4]。G.Salton等[5]提出了运用余弦方法计算信息相似度而检索信息;B.Sarwar等[6]改进了余弦相似度方法计算项目相似度,优化了相似度的计算方法;U.Shardanand等[7]用评分值中位数替代评分值均值提高了皮尔逊系数度量相似度的准确性,即CPC(constrained pearson correlation)算法;MSD(mean square difference)算法运用均方位移表示相似度,但性能较差;J.Bobadilla等[8]结合CPC算法和Jaccard系数度量相似度方法提出了JMSD(combined Jaccard and MSD)算法,虽然解决了过度依赖共同评分项的问题,但仍然存在评分值利用率低的问题;Ahn等[9]提出了PIP(proximity impact popularity)相似度度量模型,考虑用于评分的接近、影响和普及3个方面计算用户相似性,但没有考虑用户全局偏好。相似度方法及计算公式如表1所示。
| 图表编号 | XD006300100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.10.01 |
| 作者 | 杜茂康、王忠思、宋强 |
| 绘制单位 | 重庆邮电大学电子商务与现代物流重点实验室、重庆邮电大学电子商务与现代物流重点实验室、重庆市通信管理局 |
| 更多格式 | 高清、无水印(增值服务) |



![表1 颗粒增强钛基复合材料常用增强体的性能[5-6]Tab.1 Properties of reinforcements frequently-used in particle reinforced titanium matrix comp](http://bookimg.mtoou.info/tubiao/gif/SJGY201904001_06200.gif)
{kind=link}