《表1 CPU运行及GPU加速对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在将约束转化成以上粒子结构后,求解约束变为对粒子进行并行计算而不是约束,即一个线程计算出与线程对应的粒子相关的所有约束。将其对该粒子的位置修正偏移量进行叠加,最后获得粒子最终的位置。同时为了防止多个线程之间对粒子位置缓存读写冲突,通过使用2个缓存来处理该问题。一个缓存是只读缓存readBuffer,另一个是只写缓存writeBuffer,其缓存在每次迭代初始时存放的是粒子在外力作用下的预测位置。在求解约束过程中,通过从readBuffer中获得粒子的预测位置来计算粒子的位置的修正量,最后在writeBuffer中更新粒子的位置信息。在每次迭代的最后,用writeBuffer更新readBuffer的数据,以便于下次迭代的使用。加入GPU实现后的对比效果见表1。
| 图表编号 | XD0059468000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 戴莎、司伟鑫、钱银玲、郑睿、王琼、徐东亮、彭延军、王平安 |
| 绘制单位 | 武汉理工大学机电工程学院、中国科学院深圳先进技术研究院深圳市虚拟现实与人机交互技术重点实验室、中国科学院深圳先进技术研究院深圳市虚拟现实与人机交互技术重点实验室、香港中文大学计算机科学与工程系、中国科学院深圳先进技术研究院深圳市虚拟现实与人机交互技术重点实验室、中国科学院深圳先进技术研究院深圳市虚拟现实与人机交互技术重点实验室、中国科学院深圳先进技术研究院深圳市虚拟现实与人机交互技术重点实验室、武汉理工大学机电工程学院、山东科技大学信息科学与工程学院、香港中文大学计算机科学与工程系、中国科学院深圳先进技术 |
| 更多格式 | 高清、无水印(增值服务) |





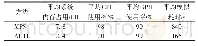
{kind=link}