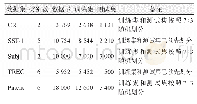
《表1 工业数据集信息:面向持续集成测试优化的强化学习奖励机制》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了确定本文方法在实际业界的适用性,本文使用工业数据集进行实验:Paint Control和IOF/ROL均来自ABB Robotics Norway2,用于测试复杂工业机器人;Google Shared Dataset(GSDTSR)是谷歌开源的数据集.这些数据集中包含超过300个集成周期中的测试用例执行结果等历史信息.表1列出了3个数据集的详细信息,包括测试用例集大小、集成周期数等.表中执行结果数指所有测试用例在整个集成过程中被执行的总次数,而失效率表示测试用例被执行的总数中失效的比重.可以看出,Paint Control数据集规模较小,同时,测试用例失效率近1/5;IOF/ROL数据集测试用例集规模中等,但失效率更大,是3个数据集中最高的;谷歌开源数据集GSDTSR测试用例集规模最大,但失效率仅0.25%,即在大量的测试用例中仅有少量的失效测试用例,在持续集成测试优化中,把大量测试用例中的少量失效测试用例优先执行,优化难度最大.
| 图表编号 | XD0056212900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 何柳柳、杨羊、李征、赵瑞莲 |
| 绘制单位 | 北京化工大学信息科学与技术学院、北京化工大学信息科学与技术学院、北京化工大学信息科学与技术学院、北京化工大学信息科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}