《表2 基于统计方法的比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
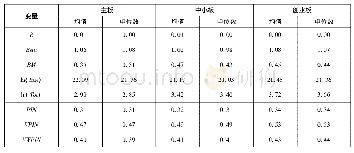
(2) 基于统计的方法。基于统计的方法就是通过对比领域相关术语与普通词汇的统计特征来进行术语的自动提取。Justeson等统计了计算词在语料库出现的频率,通过词性过滤器筛来选择候选术语。[25]Benabdallah等在准备好语料库后,用重复分段法提取所有不同的术语,并用“加权过滤器”(TF-IDF)去除一些不被认为是领域术语的词。[26]Pantel等通过结合互信息和对数似然两个参数来进行术语提取,采用互信息的方法来度量文本中两个相邻词之间的相互依赖程度,并计算出这两个相邻的词能够组成术语的可能性,从而完成术语的自动提取。[27]王强军提出基于连续指数的术语抽取,同时结合TF-IDF以及依据领域相关性考察候选术语的术语度方法来进行术语的自动提取。[28]表2比较了以上几种基于统计的方法。基于统计方法来自动提取术语可以有效识别域术语,并且此方法不需要语法和语义上的信息,不限于特定的专业领域,具有良好的可移植性,但基于统计的方法必须对整个语料库进行计算,计算量大,且在处理低频项时效果不佳。
| 图表编号 | XD0054672700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.30 |
| 作者 | 王向前、桂冬冬、李慧宗 |
| 绘制单位 | 安徽理工大学经济与管理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}