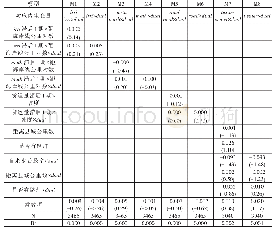
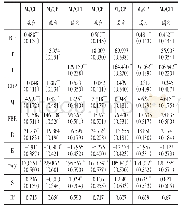
《表2 模型M0~M5的准确率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
使用训练集A2,对M0~M5进行了训练,并在测试集B上进行测试,其结果如表2所示。模型在测试集B上的准确率远高于训练集A2,表明本文使用的模型通过增量后的训练集学习到了足够多的手写风格,同时表明本文所提出的增量方法是可行且有效的。但另一方面,在经过足够多的训练次数后,训练集的准确率仍未超过90%,表明本文所使用的训练数据集可能存在某些难以识别的样本。对训练数据集进行人工排查,发现由于原始样本的分辨率过低,在增量变形的过程中,出现部分样本笔迹丢失、粘连和过度模糊的情况。如图11所示,对于同一个字符,由于过度变形,几乎完全偏离了此字的正常书写风格。正是这些过度变形后的样本模型带入的额外噪声,使得模型在训练集上表现不佳。
| 图表编号 | XD0052588000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 陈善雄、王小龙、韩旭、刘云、王明贵 |
| 绘制单位 | 西南大学计算机与信息科学学院、西南大学计算机与信息科学学院、西南大学计算机与信息科学学院、贵州工程应用技术学院彝文研究院、贵州工程应用技术学院彝文研究院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}