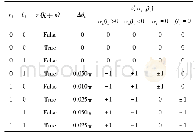
《表2 超参数取值与模型预测准确率关系表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
使用卡方选择器进行特征选择后,要利用随机森林算法进行模型的构建。在模型构建过程中,需要确定的超参数分别有决策树数(NumTrees)、决策树最大深度(MaxDepth)、不纯度度量标准(Impurity)、最大装箱数(MaxBins)、采样率(SubsamplingRate)。为了确定这5个超参数并使其得到最优的模型,需要先基于网格搜索[17]的方法得到初步模型。网格搜索法是指定参数值的一种穷举搜索方法,通过将估计函数的参数通过交叉验证的方法进行优化来得到最优的学习算法,即将各个参数可能的取值进行排列组合,列出所有可能的组合结果生成“网格”,然后将各组合用于随机森林模型训练,并使用模型在测试集上的预测准确率对表现进行评估。为了确定搜索参数,也就是手动设定的变量值中哪个是最好的,需要一个比较理想的评分方式,这个评分方式要根据实际情况确定,可能是accuracy、f1-score、f-beta、pricise、recall等,最终选择accuracy对结果进行评估。本文设定的随机森林模型相关的超参数为:NumTrees在数组[25,26,27,28,29,30,31,32,33,34,35,36,37]范围内取值,Impurity在数组[entropy,gini]范围内取值,MaxDepth在数组[15,16,17,18,19,20,21,22,23,24,25]范围内取值,MaxBins在数组[10,15,17,20,25,30,35,40,41,42,43,44,45]范围内取值,SubsamplingRate在数组[0.67,0.7,0.75,0.8]范围内取值。然后遍历所有的参数组合训练模型,最后按照预测准确率从高到低进行展示。最终形成的超参数取值与模型预测准确率之间的关系如表2所示。
| 图表编号 | XD0050596200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 刘伟、徐文峰 |
| 绘制单位 | 湖北华中电力科技开发有限责任公司、湖北华中电力科技开发有限责任公司 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}