《表1 3种图像视觉识别模型对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
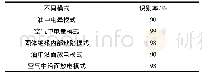
在前文中,研究已经综合探讨了3种图像视觉识别算法。其中,DenseNet是基于GoogLeNet和ResNet两个模型提出的。3种图像视觉识别模型对比见表1。由表1可以看出,GoogLeNet[23]最早进入公众视野,但是其性能却逊色于后来的2个模型,其参数较多,并且容易产生过拟合,若训练集有限,这一特征将更加明显;一旦训练的网络越大,那么该模型的计算复杂度就会越大,难以应用到实际场景中。针对不同的应用场景,3个模型的优势领域也不一样。其中,ResNet和DenseNet更能受到广大研究学者的推崇与青睐,其核心思想均是适用于Highway Nets小数据集的时候。因为数据集小,就容易产生过拟合,而DenseNet能更好地解决过拟合问题,其泛化性能也更好。但是,对于较大的数据集,ResNet的性能要更胜一筹,并且速度相对于DenseNet算法来说也更快。究其原因就在于,DenseNet每一层都需要用到前面所有层的特征。这样看来,DenseNet即便改善了算法精度,解决了过拟合问题,而且泛化性能有所提高,但是该算法对硬件内存占用却会随着数据集增大而逐步提高,对于硬件环境是非常不友好的。因此在设计中就需要根据不同的应用场景已知的既有条件来选择研究使用的模型。
| 图表编号 | XD0050511800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 任萌 |
| 绘制单位 | 西安石油大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}