《表2 分类识别模型实验结果汇总表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
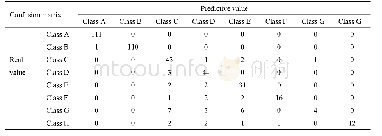
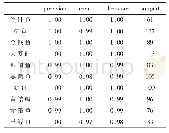
(1) 对分类识别模型的实验结果可如表2所示。从表2中可以看出,用分类识别模型分别对训练集数据、整体数据和测试集数据进行识别,预测准确率分别为99.1928%、96.2053%和94.8029%,呈逐渐下降趋势。原因在于训练集的数据就是在建立分类识别模型时进行学习训练的数据集,其准确率才高达99.1928%,这恰好说明分类识别模型对训练集的训练效果是非常好的,但这个结果不具有实践意义;其次分类识别模型对整体数据的识别准确率低于训练集数据,是由于1673条记录中除了训练集的1115条被学习过的记录外还存在558条没有被学习过的记录,这个结果合乎情理;最后分类识别模型对测试集数据的识别准确率相对于前两种最低,是因为对识别模型来说测试集的558条记录完全是陌生的,完全是靠记忆训练集的特征来进行识别的,这也真正代表了分类识别模型的识别水平,具有实践价值。94.8029%的识别准确率意味着在对会计信息是否失真的识别中,能够有94.8029%的失真信息被识别,有助于相关人员较为全面的了解会计信息的真实性。
| 图表编号 | XD0050185500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.10 |
| 作者 | 张志恒、邓启兰 |
| 绘制单位 | 重庆理工大学会计学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}