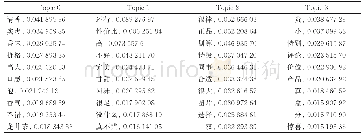
《表3 基于LDA模型的政策主题分析结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《政策与部门视角下中国网络空间治理——基于LDA和SNA的大数据分析》
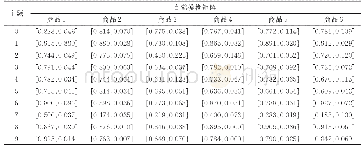
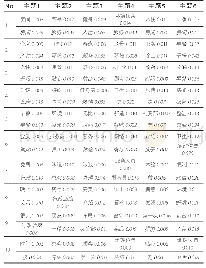
实验在Python程序下进行,结合sklearn(2)、matplotlib(3)等几个常用的数据分析包,将清洗完成后的6 445个关键词进行LDA建模分析。文本的分类主题是建立在主题词聚类基础上相对抽象的概念,根据不同粒度划分可计算出不同的主题数量,因此需要结合需求,对结果进行不断调试以达到最优求解。考虑到本研究中政策文本涉及部门数目较多,涉及面较广,选取的潜在主题数目分别为6个、8个、10个、15个和20个。根据不同数量的分类主题/主题词列表可以发现,当分类主题总数为15时,列表的语义提取效果最好。限于篇幅,这里在表中展示了15个潜在主题、概率指数前10位的主题词列表,部分结果如表3所示。
| 图表编号 | XD0050040700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.03.01 |
| 作者 | 张毅、杨奕、邓雯 |
| 绘制单位 | 华中科技大学公共管理学院、华中科技大学公共管理学院、华中科技大学公共管理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}