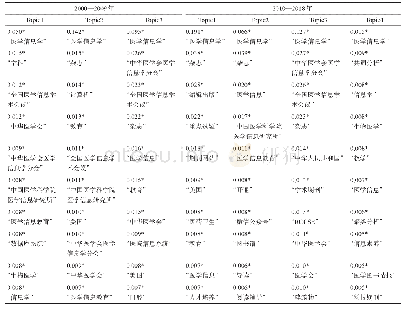
《表3 国内2000—2009年和2010—2018年医学信息学LDA主题模型分析结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《21世纪以来医学信息学研究走向及其健康信息学转向》
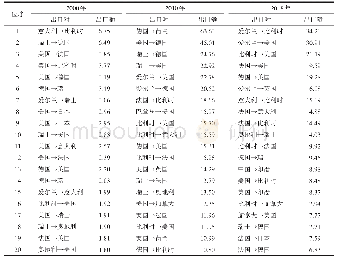
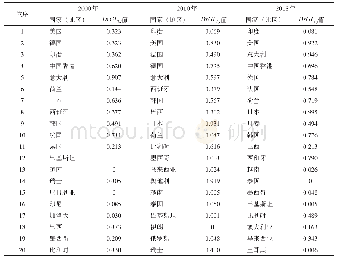
读取国际Web of Science和国内CNKI全记录文本数据,通过Python的Gensim工具包中的LDA模型,设置超参数alpha=50/k,进行预处理操作,由于传统分词方式无法还原医学信息学领域中英文大量的专业名词,如“Medical Informatics”、“医学信息学”等,所以本文国际数据基于美国国立医学图书馆MESH医学主题词库(55742条),国内数据基于结巴(jieba)内置分词,并结合VOSviewer共现关键词,获得国际、国内合计10739个词,提取国际、国内每篇文档中相应主题和关键词,用Gibbs Sampling随机抽样算法,进行最大正则匹配,并过滤特色字符、常见缩写单词,清洗停用词,去除无特征意义的单词,对各种形式单词进行词性还原和相应归并,参考Vosviewer模块化主题聚类,选取每一个主题中概率最高的10个词进行抽象概括,数据结果如表2和表3所示,解读结果如下。
| 图表编号 | XD00168293300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.24 |
| 作者 | 徐璐璐、杜建、叶鹰 |
| 绘制单位 | 江苏省数据工程与知识服务重点实验室南京大学信息管理学院、南通大学图书馆、北京大学健康医疗大数据研究中心、江苏省数据工程与知识服务重点实验室南京大学信息管理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}