《表2 政策文本主题词提取算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《政策与部门视角下中国网络空间治理——基于LDA和SNA的大数据分析》
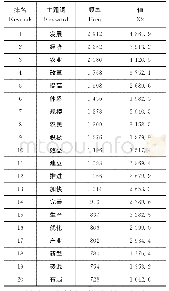
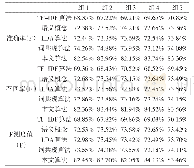
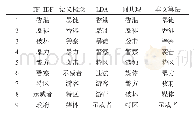
针对政策文本的数据集合,采用LDA挖掘指定个数的主题词,可以实现对文本主题词抽取的量化处理。这些主题代表一个文本,以实现特征降维的作用。LDA模型分析过程为:主题词提取→建立分类主题→概率统计及排序。(1)主题词提取,根据主题词的不同含义,将其归类至不同的分类主题中;(2)建立分类主题,含义相近的特征词分别标注为对应的主题;(3)概率统计及排序,统计每个分类主题的概率值并排序。LDA主题词提取算法如表2所示。其中,α、β为先验参数;θ、φ为两个需要估计的参数;文本总量用M表示;W代表词典大小;K为主题数量;Nm为文本m的长度。在这里需要解释的一点是,在文本获取之前,算法事先并不知道这些主题,笔者也未预先设计已有的主题词或分类主题。
| 图表编号 | XD0050040400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.03.01 |
| 作者 | 张毅、杨奕、邓雯 |
| 绘制单位 | 华中科技大学公共管理学院、华中科技大学公共管理学院、华中科技大学公共管理学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}