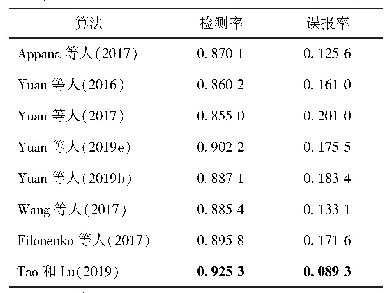
《表4 MSCOCO数据集下的性能指标比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
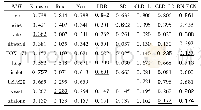
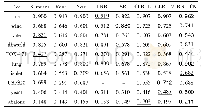
图4为在TIC模型下的图像描述生成的实验结果,图4上方是输入的图片,下方是图片对应的描述.表3为句子生成多样性结果的举例,带有三角形标注的是训练后生成的不属于训练集里的描述,可以看出TIC方法在BLEU-n,METEOR,CIDER,ROUGE提高的基础上对句子生成的多样性方面依然有一定的保证,也具有一定的新颖性,因此证明TIC生成句子具有多样性.表4为MSCOCO数据集下各方法的比较结果.可以看出,TIC在MSCOCO数据集上BLEU-1,BLUE-2,METE-OR,CIDER,ROUGE分别提高了0.7,0.8,0.4,1.3,0.3.由于TIC的Decoder考虑到了不同主题下的词分布,生成的句子的准确率更高,所以BLEU-1,BLUE-2匹配句子上表现较好,ME-TEOR,CIDER指标分数相比其他方法要高.但随BLEU-n中n的增加,样本的数量比较小,在句子层面上的匹配就会越来越差,所以BLEU-3,BLEU-4的结果并没有达到理想结果,ROUGE与BLEU-n相似.表5为Flickr8k数据集下各方法的比较结果.TIC在Flickr8k数据集上BLEU-1,BLUE-2,METE-OR,ROUGE分别提高了1.3,1.2,0.6,0.2.表6为Flickr30k数据集下各方法的比较结果.TIC在Flickr30k数据集上BLEU-1,BLUE-2,METEOR,ROUGE分别提高了1.3,1.3,0.7,0.6.由于Flickr8k数据集和Flickr30k数据集的主题数据集样本较少,所以较MSCOCO数据集提高的并不是很明显.
| 图表编号 | XD0045033500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 李晓莉、张慧明、李晓光 |
| 绘制单位 | 辽宁大学信息学院、辽宁大学信息学院、辽宁大学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}