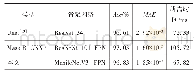
《表4 不同方法在MSCOCO数据集上的效果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:加粗字体表示效果最优,“—”表示结果未知。
不同方法在MSCOCO数据集上的效果对比如表4所示。表4中,DeepVS(deep visual-semantic)是Karpathy和Li(2015)提出的一种图像字幕生成方法,该方法结合了目标检测方法,通过对图像中各个物体的精准识别,获取到更好的图像特征,从而在预测过程中提高了生成字幕在评价指标上的得分。NIC(neural image caption)是由Vinyals等人(2015)提出的,该方法将编码器—解码器框架应用于图像字幕生成任务,使用CNN作为编码器,LSTM作为解码器,最终形成一个端到端的字幕生成网络。gL-STM(guiding long-short term memory)是由Jia等人(2015)提出的,该方法在使用LSTM生成字幕时额外加入了新的指导信息以提高生成字幕的质量。RLF(reinforcement learning with feedback)由Ling和Fidler(2017)提出,该方法在强化学习的基础上加入了一个反馈网络以达到指导网络生成字幕的目的。IRBO(image description generation by modeling the relationship between objects)是Bai等人(2018)提出的一种通过目标检测方法提取图像特征并在对象之间建立关系模型的方法,该方法根据对象及对象之间的关系生成图像字幕。FFGS(feature fusion with gating structure)是Yuan等人(2017)提出的另一种图像字幕生成方法,该方法提出一种基于门控结构的特征融合方法,将不同维度的图像特征融合并输入到LSTM网络进行字幕生成。
| 图表编号 | XD00143030000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.16 |
| 作者 | 杜海骏、刘学亮 |
| 绘制单位 | 合肥工业大学计算机与信息学院、合肥工业大学计算机与信息学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}