《表2 MLPClassifier和dCNN模型参数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
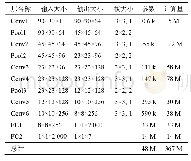
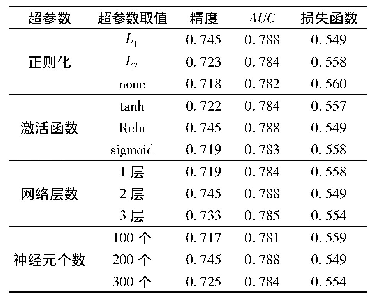
将训练数据和验证数据合并为正常数据,攻击数据一共包含6种攻击类型,故整个数据集一共包含7种标签类型。采用词袋模型对数据进行特征化,特征化后,每个数据样本包含167个特征。然后,使用数据预处理模块按照图2所示的算法将数据扩展到196个特征并进行填充,再将其转换为14×14的二维数据。取其中30%作为测试集,70%作为训练集。将训练数据送入模型进行40次迭代训练。训练结束后,使用测试集进行测试,并将本文方法测试结果同主流机器学习库Scikit-learn[27]中的MLPClassifier分类器(表3中缩写为MLP)产生的结果进行比较。MLPClassifier采用两个隐藏层,每个隐藏层包含1 000个隐藏神经元,共进行1 000次迭代训练。另外,MLPClassifer使用L2正则化防止过拟合,使用主成分分析进行降维,主成分取k=60。两个模型的参数设置如表2所示。其中:λ为L2正则项系数,ε为ADAM算法修正因子。测试结果如表3所示,其混淆矩阵如图7所示。
| 图表编号 | XD0039167600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 张思聪、谢晓尧、徐洋 |
| 绘制单位 | 贵州大学计算机科学与技术学院、贵州师范大学贵州省信息与计算科学重点实验室、贵州师范大学贵州省信息与计算科学重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}