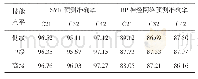
《表7 基于前引专利数量的模型预测准确率分布》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
除此之外,考虑到前引专利的相关特征,样本中约10%的专利并未有任何前引专利,将直接提升模型对其特征的抓取难度和预测难度。因此,表7罗列了前引专利数量对于模型对测试集专利进行预测的准确率分布。如表7所示,在测试集中,未含有任何前引专利的样本其后引次数,以及模型的预测准确率都明显低于其他样本专利。换言之,如果一个专利申请未含有任何前引专利,虽然体现了其高度新颖性,但是其质量具有更大的不确定性。其后引次数可能较低,并且较难被预测。
| 图表编号 | XD0039056100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.24 |
| 作者 | 刘夏、黄灿、余骁锋 |
| 绘制单位 | 浙江大学管理学院知识产权管理研究所、浙江大学管理学院知识产权管理研究所、香港科技大学计算机科学及工程学系 |
| 更多格式 | 高清、无水印(增值服务) |


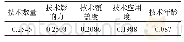
{kind=link}